

Data Flow Explained: How Nodes Process Blocks
IOTA 2.0 Introduction Part 3
TL;DR:
This blog post delves into the functionality of IOTA 2.0 through its Data Flow, the process by which data is used to construct the network and generate further data for propagation. The IOTA protocol comprises three layers: Network, Communication, and Application. Nodes in the Network Layer exchange data necessary for operations, while the Communication Layer manages block connections in the Tangle using Rate Control and Congestion Control. The Application Layer handles block contents and payloads, thereby maintaining the ledger state and enabling consensus. The Data Flow breaks down block processing into components like Parser, Storage, Solidifier, Booker, Scheduler, and Tip Manager. This intricate system ensures the efficient and robust functioning of IOTA 2.0, even under high congestion.
How does IOTA work? There’s no one-line answer to this question, as IOTA is the result of years of researching and iterating solutions until arriving at something that has extraordinary performance while still aligned with our vision. (If you want to read more about our vision, head back to Digital Autonomy for Everyone: The Future of IOTA).
The lack of a one-line answer doesn’t mean there is no answer! One way to understand IOTA 2.0 is from the perspective of its Data Flow. Data Flow is what we call the process of how the data you share with the ledger is used to build the network, and how the network generates further data to be propagated. Understanding Data Flow means understanding how each module of the protocol interacts with the data you share with it.
Here's the simplest answer to the question “How does IOTA work?” As always, for a more technical answer, read the Wiki version of this article.
The IOTA 2.0 Protocol Structure
The IOTA 2.0 protocol is structured into three distinct layers, each serving a specific purpose in managing nodes, blocks, and payloads.
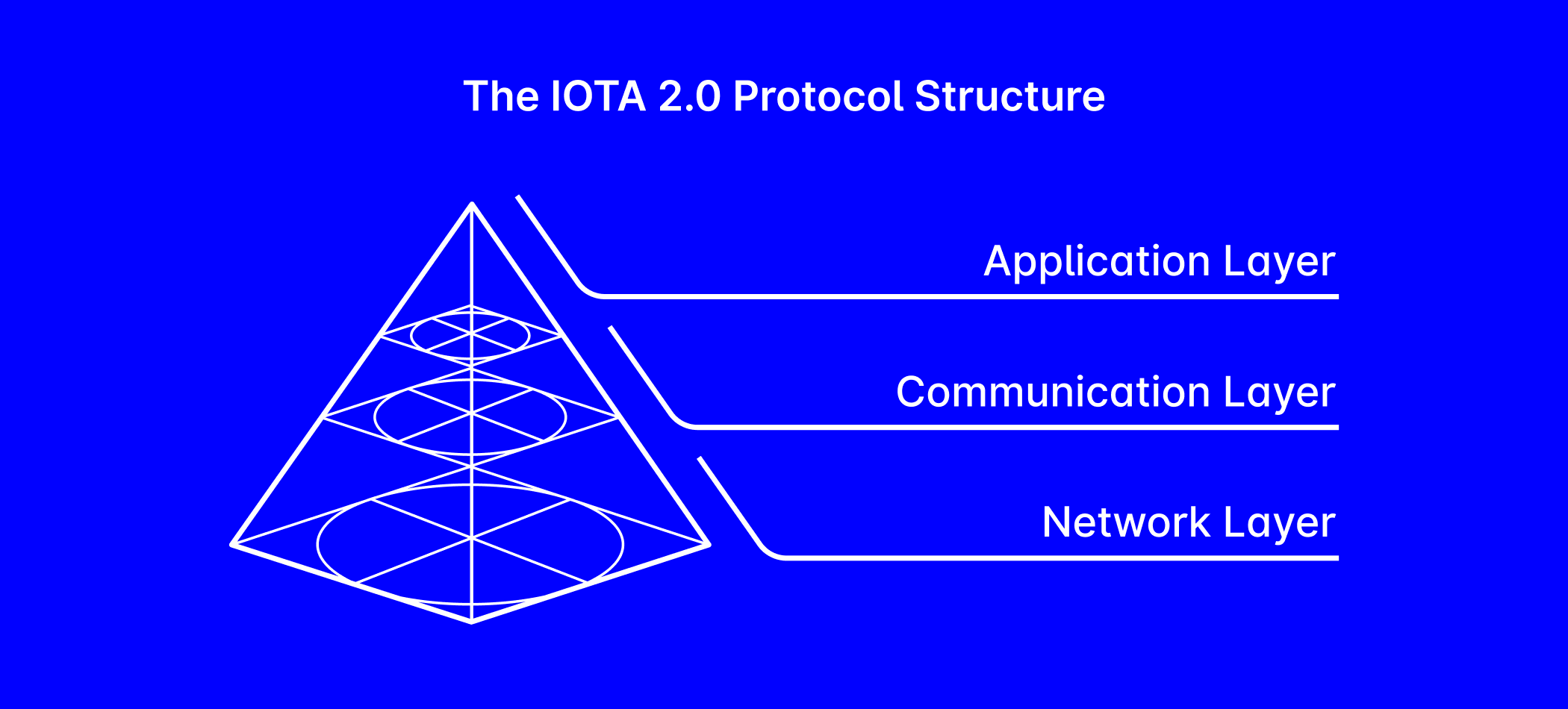
- At the bottom of the pyramid is the Network Layer, which is a network of nodes that exchange the data necessary for everything to function: i.e. blocks and packets of information used by the protocol. To optimize their hardware resources, nodes only need to maintain a connection with a limited number of other nodes. The peer-to-peer network of these nodes is the Network Layer. The Peer Discovery and Neighbor Selection modules randomly select neighboring nodes, bolstering network resilience by preventing simple attacks.
- Blocks that arrive via the network layer must connect with other blocks by establishing references to them. These connections form the Directed Acyclic Graph (DAG) as we know it – in other words, the Tangle! The Communication Layer regulates the blocks that build the Tangle and is handled by the modules that control the flow of information: Rate Control and Congestion Control.
- The contents of blocks and their payloads are handled by the Application Layer. Payloads contain the data that will be used by applications, including crucial components like Consensus and Notarization. These elements enable consensus between nodes regarding block inclusion in the Tangle and validation of transactions (you can read more about our consensus in A New Consensus Model, Part 6 of our blog post series). Because achieving agreement on data is the most important problem for DLTs, the Application Layer is responsible for maintaining the ledger state.
Breaking Down the Data Flow
When you create a block on IOTA 2.0, it first enters the Network Layer, where a careful process unfolds before the node can process all your block’s information and make any necessary changes required by this new information.
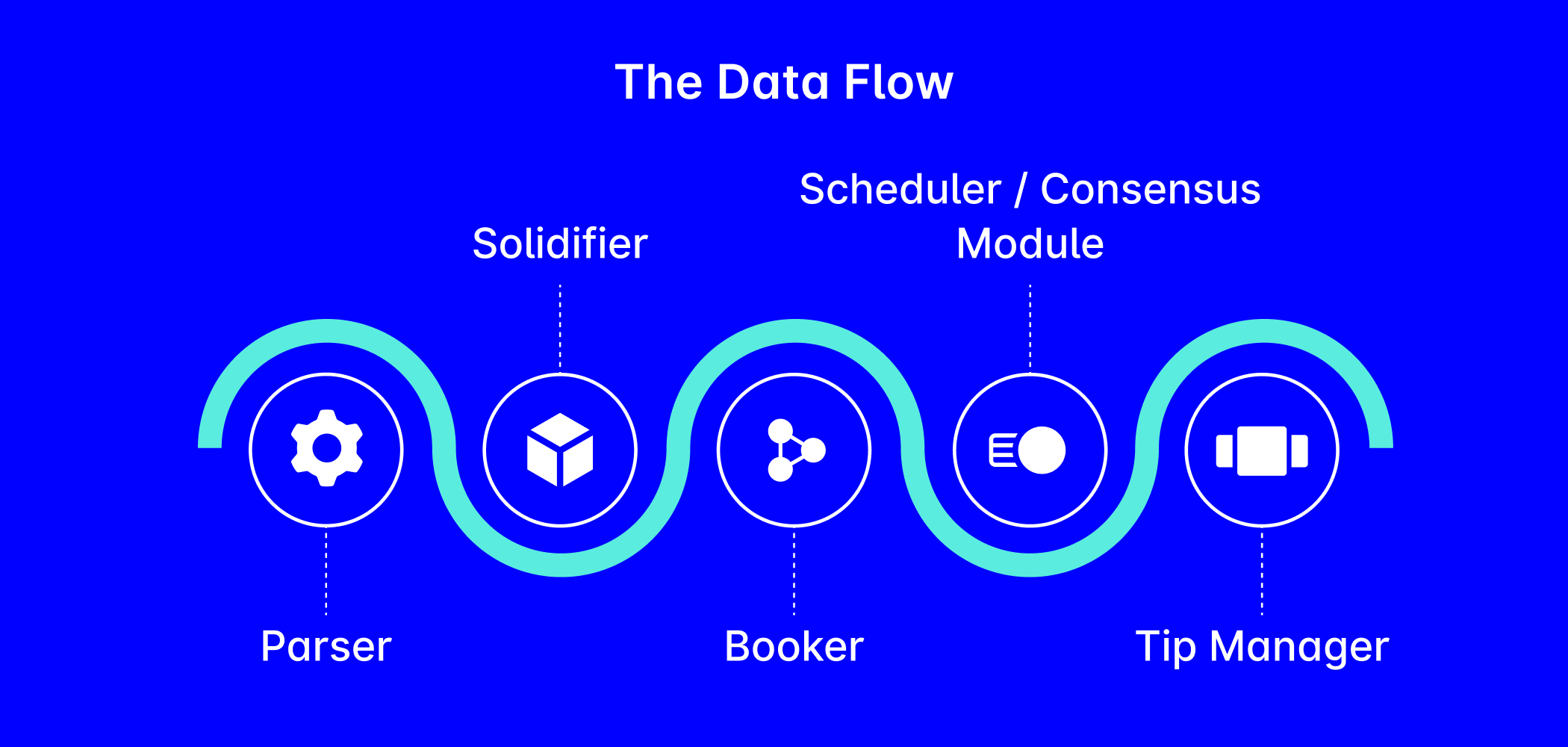
The Data Flow separates this procedure into six distinct components, ensuring that the data is properly handled. These components are the Parser, Solidifier, Booker, Scheduler, and Tip Manager. Let’s take a look at each of these components to understand how they shape our protocol!
- Parser: As the first step for blocks arriving at a node, the Parser interprets the received bytes and turns them into usable information for the other components of the process. The parser filters out redundant or invalid information (for example, when multiple copies of a block are received from neighbors, if a mistake was made in the hashing process, or if information was lost due to a communication error). The Parser checks the correctness of the translated information, such as the block’s timestamp, Mana burn, slot commitment age, and signature (Don’t worry if any of these topics are unfamiliar to you: later blog posts in this series explain it all!).
- Solidifier: Solid blocks maintain consistent connections to past blocks, preventing information gaps when retracing previous block history. The Solidifier ensures that the data it processes is solid (or, if not, that it doesn’t proceed any further in the Data Flow). If any blocks are missing, it requests the information from neighboring nodes. New nodes joining the network can also use the solidifier to establish a history of the ledger and bootstrap an otherwise empty database!
- Booker: Responsible for keeping order in the Tangle and the ledger, the booker arranges received blocks and transactions, identifies conflicts, and establishes possible conflicts in the conflict DAG (more on this in Part 6, A New Consensus Model), which results in differences that need to be resolved by the consensus module. It adds blocks to the Tangle and applies the changes in the corresponding ledger reality.
- Scheduler: Serving as the gatekeeper of the Gossip protocol (which relays information to neighboring nodes), the Scheduler queues blocks based on their issuer and selects blocks for further gossiping and/or inclusion in tip pools according to the issuer’s rate. It protects against spam, maintains order during congestion, and ensures that access to the Tangle remains functional and fair!
- Consensus: In parallel to the Scheduler, the booked blocks go to the Consensus module. This is where the Approval and Witness Weights are propagated and tracked, and where the blocks and transactions are flagged as accepted and confirmed when these weights pass a certain threshold. This module is the one that keeps the confirmation moving forward!
- Tip Manager: The tip manager adds blocks selected by the scheduler into the tip pool. It also keeps the local tip pool of a node in order by removing newly approved or very old blocks.
There's also a supplementary component that is used when the node itself is creating the block:
- Block Factory: As the name suggests, this is where new blocks are formed! Based on information provided by the user, a payload is generated and fed to the factory where the block is created by selecting tips to be approved using the Tip Selection Algorithm (find out more about tip selection in "Understanding Congestion Control", Part 8 of this blog post series, published on October 23rd). Then, the slot commitment is fetched (slot commitments are described in Part 6), the timestamp is registered and, finally, all information is signed. This adheres to the creation rate set by the Rate Setter, which is an element of our congestion control mechanism.
The data flow is the first step to understanding the IOTA 2.0 protocol, from the point of view of the block as it traverses nodes and metamorphoses into fresh Tangle data and ledger content. This process is the result of a deeply iterated and deliberated system that is not only robust but extremely efficient, even during high congestion.
Forthcoming blog posts will explore these aspects in greater depth, beginning with Data Structures Explained: The Parts That Make the Tangle.
Join the conversation on X
🌐You skimmed the overview of how #IOTA 2.0 #DataFlow works, but it left you wanting more? Look no further, because this Wiki article provides a detailed description of the interaction between the IOTA 2.0 protocol components 🔗https://t.co/D9mS0WMi1g
— IOTA (@iota) October 10, 2023
IOTA 2.0 Introduction
Part 1: Digital Autonomy for Everyone: The Future of IOTA
Part 2: Five Principles: The Fundamentals That Every DLT Needs
Part 3: Data Flow Explained: How Nodes Process Blocks
Part 4: Data Structures Explained: The Building Blocks that Make the Tangle
Part 5: Accounts, Tokens, Mana and Staking
Part 6: A New Consensus Model: Nakamoto Consensus on a DAG
Part 7: Confirming Blocks: How Validators Operate
Part 8: Congestion Control: Regulating Access in a Permissionless System
Part 9: Finality Explained: How Nodes Sync the Ledger
Part 10: An Obvious Choice: Why DAGs Over Blockchains?
Part 11: What Makes IOTA 2.0 Secure?
Part 12: Dynamic Availability: Protocol-Based Assurances
Part 13: Fair Tokenomics for all Token Holders
Part 14: UTXO vs Accounts: Merging the Best of Both Worlds
Part 15: No Mempool, No MEV: Protecting Users Against Value Extraction
Part 16: Accessible Writing: Lowering the Barriers to Entry


