

Honest Data

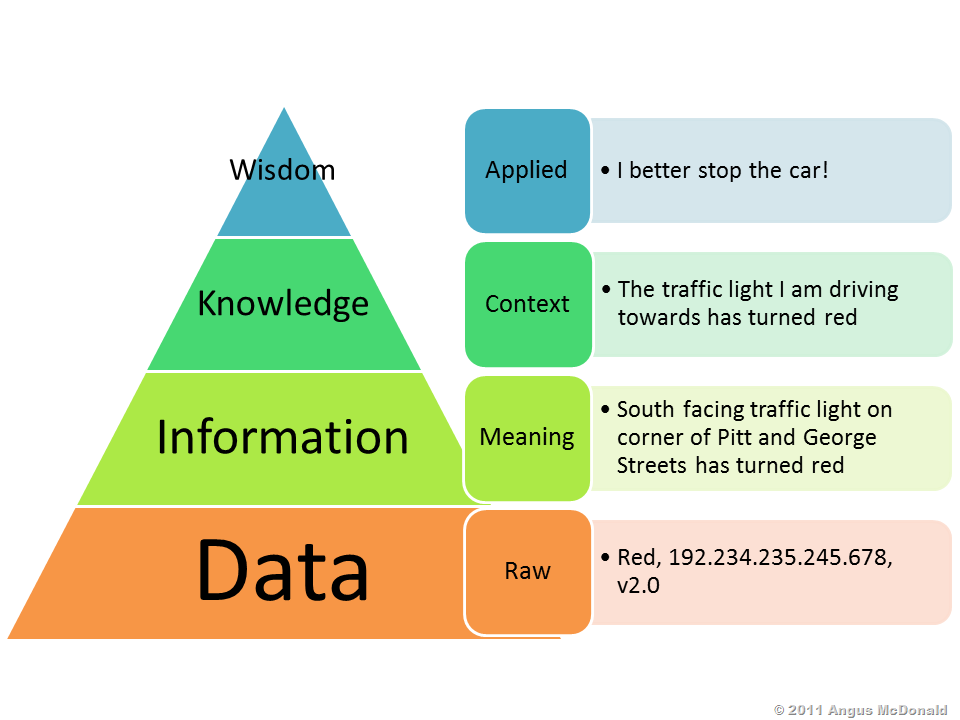
Data is the seed from which information, knowledge and wisdom sprouts and blossoms. The photons hitting your eye-lenses, the sound waves traveling into your ear canal and the nerves in your skin firing in response to anything tactile is raw data. Our brains tend to trust that this data is honest, a reflection of its true environment, so automatically the brain extract information from it and knowledge is established in the mind, which is how we are able to do virtually everything that we do. In brief:data is tremendously important.
But what happens if the data is corrupted somehow? The DIKW pyramid collapses. The information derived from it and therefore the knowledge we and increasingly our devices base decisions on, will be erroneous. We will see, as we are ever more relying on automated Big Data, that this can be very costly and even deadly.

In order to put the topic into tangible terms let’s explore a use case from the real world that fundamentally relies on data integrity, and which marries Internet-of-Things with economics. Index-based rainfall insurance. In the life of farmers in emerging economies like Kenya, the yield from a harvest, or lack thereof, can mean the very real difference between being able to afford necessities and that of being broke with malnutrition and starving. Droughts can render a whole summer of hard labour and life savings wasted. Therefore insurance providers and farmers have begun adopting an innovative insurance model where the farmers get paid if there is not sufficient rain in a season to have a successful crop. This model relies on data from local IoT weather stations which decide whether a payout is due or not. This is very efficient as it gets rid of the expensive and error-prone human component for the insurance company who would otherwise have to go and check the claims locally for every crop and settle a claim with every farmer manually. However because data is now the sole decider of whether money moves from Party A (insurance provider) to Party B (the insured) there is a direct incentive for both parties to alter the data in their favor. So with this example in mind let’s delve into data integrity and its vital role.
In brief terms ‘Data Integrity’ refer to the fact that you can rely on the data being honest and intact. Genuine. Unfortunately as we are starting to explore in this article there are very overwhelming incentives to tamper with data, and in the current status quo it happens all the time.
There are essentially 2 methods one can utilize in order to falsify data. Hardware and software. The first is to ‘censor the sensor’. This is easily achieved by preventing the sensor from collecting real data of its environment by feeding it false input. In our aforementioned scenario one could achieve this simply by putting an umbrella over the rainfall sensor, this would immediately render the weather station’s data invalid. In other words:Garbage Input equals Garbage Output.The solution to mitigate this fundamental hardware obstacle of data integrity is to keep the location of the sensors secret and/or monitored, and have Byzantine fault tolerant redundancyI.E. more sensors generating data for comparison. Fortunately for the sake of data integrity this method of ‘censoring the sensors’ require the dishonest party to first locate the sensor(s) and then invest continuous effort to manipulate its input, all while avoid being detected doing it.
The other, more potent method of falsifying data is to tamper with it after it has been put into a central database. The sensor can be doing its job perfectly, accurately logging the amount of rainfall, but this is all for naught if the data is then manipulated afterwards. For the insurance companies with direct access to the database this is literally as easy as the click of a button. For the other party (the insured) it presents a challenge of gaining access, but this is easily achieved by hacking into the database or having someone disloyal on the inside alter it on their behalf. Insurance is just one ofcountlessindustries where this applies. These range from relatively innocuous tampering to matter of life and death.

There areendless examplesof students breaking into their school’s central database to alter their grades favorably.
In our age of digital medical records this presents daunting potential for devastation. It’s not hard to imagine a nefarious blackhat or cyberterrorist alter a hospital’s database containing medical records which inform what kinds of drugs and dosages each patient is to take. Such a scenario quickly turns lethal by the touch of a few buttons. Similarly inclinical drug trialsthere is a strong incentive to modify the data or milestones in a study after the fact which leads to wasted funding in the best case scenario, and dangerous drugs on the market in the worst case. Finally as we are sprinting into an exciting time of wearables, brain-interfacing and biotech-implants, the importance of data integrity will become even orders of magnitude more important year by year.
A last reality check exercise comes from contemplating that we are on the cusp of the autonomous era, which brings with it responsibility-by-proxy. It’s natural to envisage companies which manufacture driverless vehicles having a very compelling incentive to alter the data of their cars’ blackbox if it reveals that their engineering, and not the actions of the deceased driver was at fault for a tragedy.
These examples and an unlimited plethora of others reveals an urgent need for a solution to the issue of data integrity in our old database infrastructure, but even more so in the new emerging IoT-based ones. Fortunately such a solution exist.

Tangle— the permissionless distributed ledger ofIOTA— solves this issue through guaranteeing data integrity by storing the data in a distributed and trustless fashion among the nodes in the network. It is now publicly auditable because everyone in the connected cluster has a copy of it. This gets rid of the single point of failure. It is now impossible for someone to alter the original data without the rest of the network seeing that it is now incompatible with their copy. Data Integrity is ensured.

Furthermore unlike old blockchains where it costs money to send/store data, it is entirely free in the IOTA network. Similarly in the old blockchain architecture data transfers bloats and slows down the network, in IOTA’s Tangle it actually strengthens the security of the network and makes it even more efficient. Finally due to the unique architecture of the Tangle ledger it allows for partitioning of the network, meaning that you can branch off clusters from the main-Tangle and establish local networks that still ensure data integrity without having to worry about continuous internet connection.
Of course there is no reason to store the whole dataset in the Tangle ledger, all you need is to store the hashes.Hashesare the equivalent of biometrics for data, if you alter the content of the data — its DNA — you will get a different hash, revealing that it has been tampered with.IOTA Tangle is specifically engineered to be the medium for sending data to ensure it’s integrity, even at the edge of the network.


