
The Tangle: an Illustrated Introduction
Part 2
In the previous article in the series, we introduced the Tangle as a data structure. We also learned about tips and the importance of choosing a good tip-selection algorithm. Today we will learn about transaction rates and network latency, and the role they play in determining the shape of the Tangle. We will also learn about the unweighted random walk, which will be further developed next week.
In last week’s simulation, you may have noticed that transactions are not evenly spread out across time and some periods are “busier” than others. This randomness, which makes the model more realistic, is achieved by using a Poisson point process to model how transactions arrive. This model is very common for analyzing how many customers walk into a store in a given time period, or how many phone calls are made to a call center. We can see this behavior in the example Tangle below. Transactions 4, 5, and 6 arrived almost simultaneously, and after transaction 6 there was a long pause.

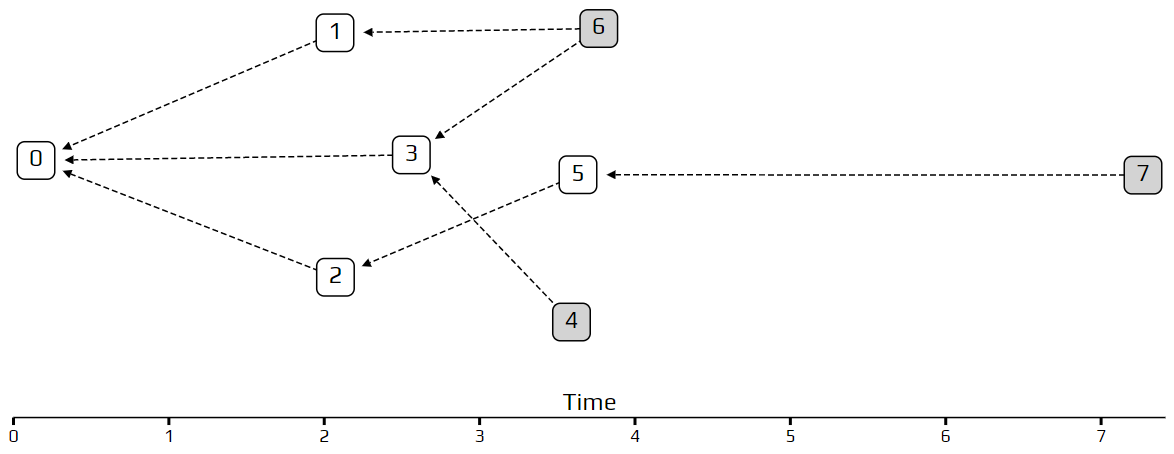
For our purposes, we only need to know one thing about this Poisson point process: on average, the rate of incoming transactions is constant and is set by a number we call λ. As an example, if we set λ=2, and the number of transactions to be 100, the total simulation time will be about 50 time units. Try it out!
One more interesting thing to point out, before moving on: if we set λ to a very small amount (say 0.1), we get a “chain". A chain is a Tangle where transactions only approve one previous transaction, instead of two. This happens because transactions are coming in so slowly that at any given time there is only a single tip to approve. In the other extreme, with huge λ, all of the transactions arrive so fast that the only tip they see is the genesis. This is just a limitation of the simulation: with large λ and a fixed number of transactions, we are simulating a very short time period.
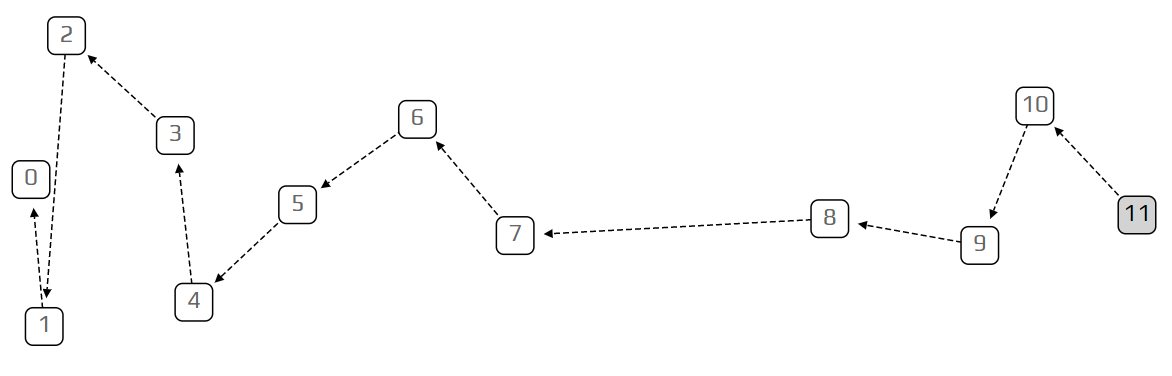
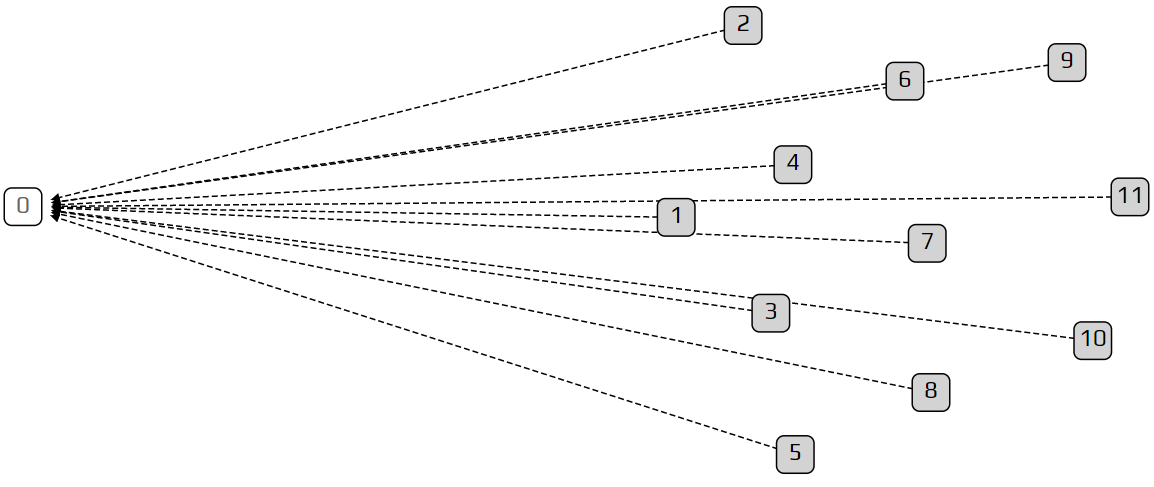
So what do we mean by the transaction not “seeing” a previous one? In the model, we make each transaction invisible for a certain period after it arrives. We mark this delay period with the letter h. This delay represents the time it takes for the transaction to be prepared and propagated through the network. In our simulation, we always set h=1. This means we can only approve transactions that are at least one time unit in the past. This delay is not just a minor detail that was put in for extra realism, but a fundamental property of the Tangle, without which we will always get a very boring chain. It also brings the Tangle closer to the real world, where it takes some time for people to tell each other about new transactions.
Finally, it’s time to talk about a more advanced tip selection algorithm: the unweighted random walk. Using this algorithm, we put a walker on the genesis transaction and have it start “walking” toward the tips. On each step, it jumps to one of the transactions which directly approves the one we are currently on. We choose which transaction to jump to with equal probability, which is where the term unweighted comes from. Naturally, we’ve made a simulation that shows how this happens.
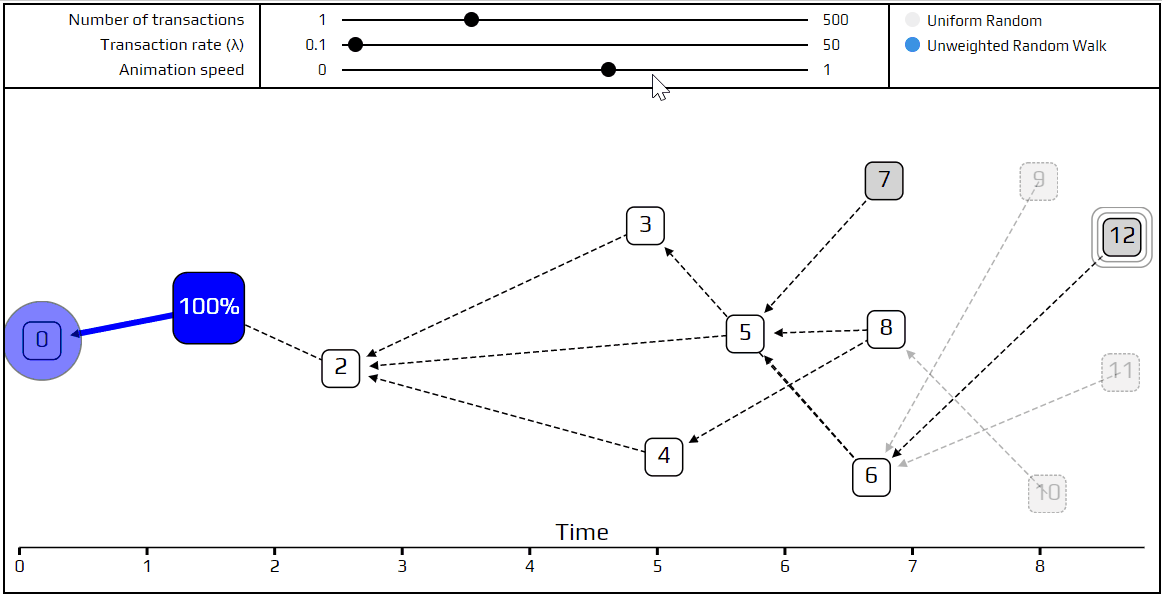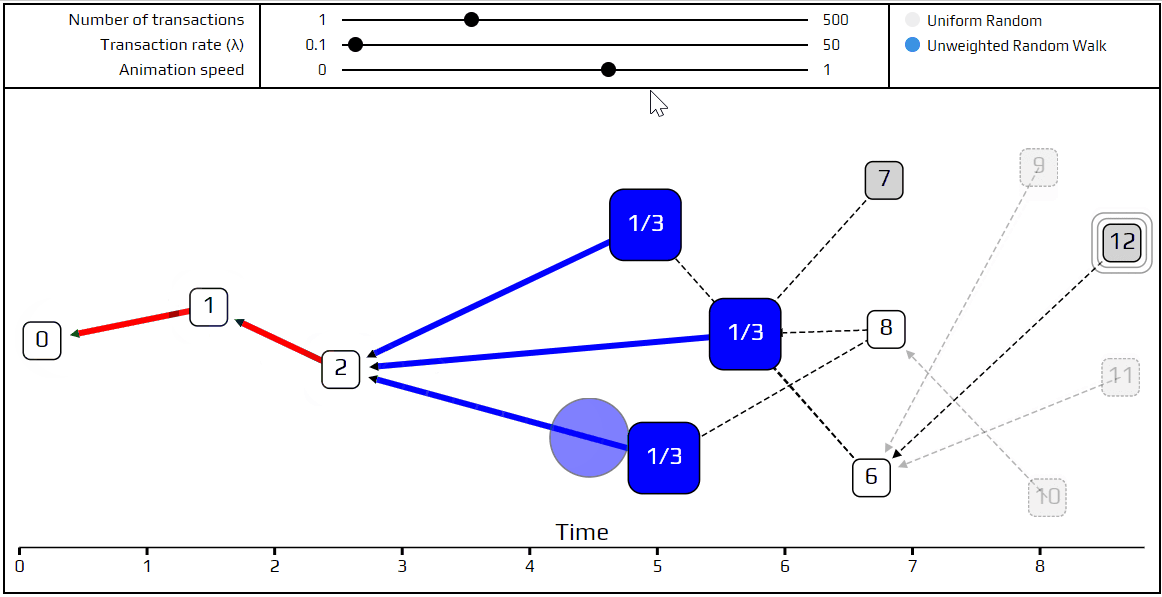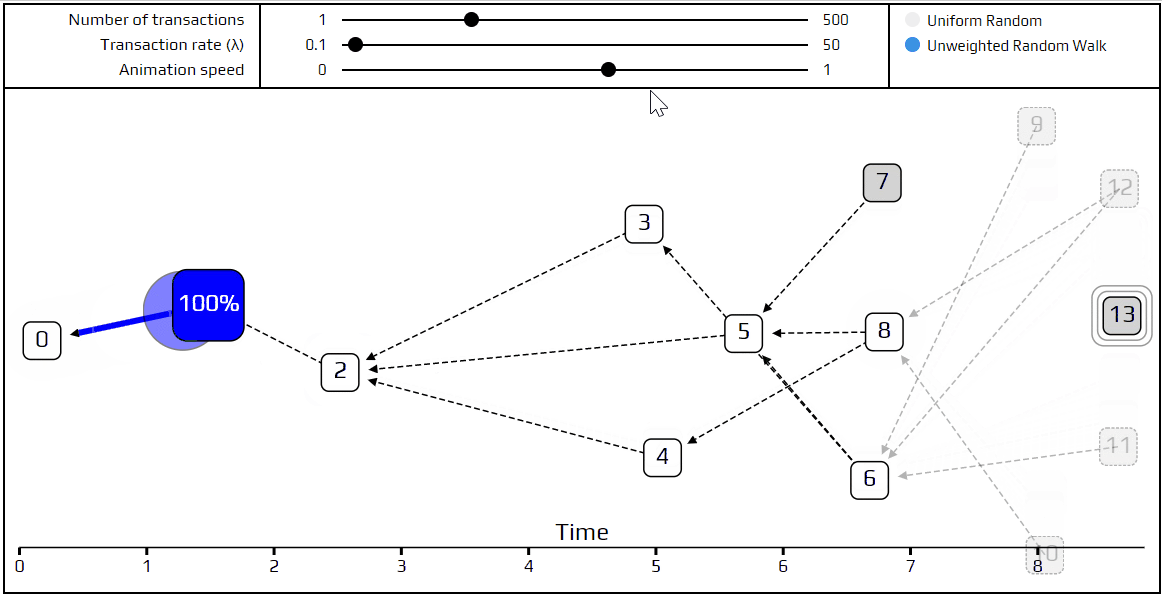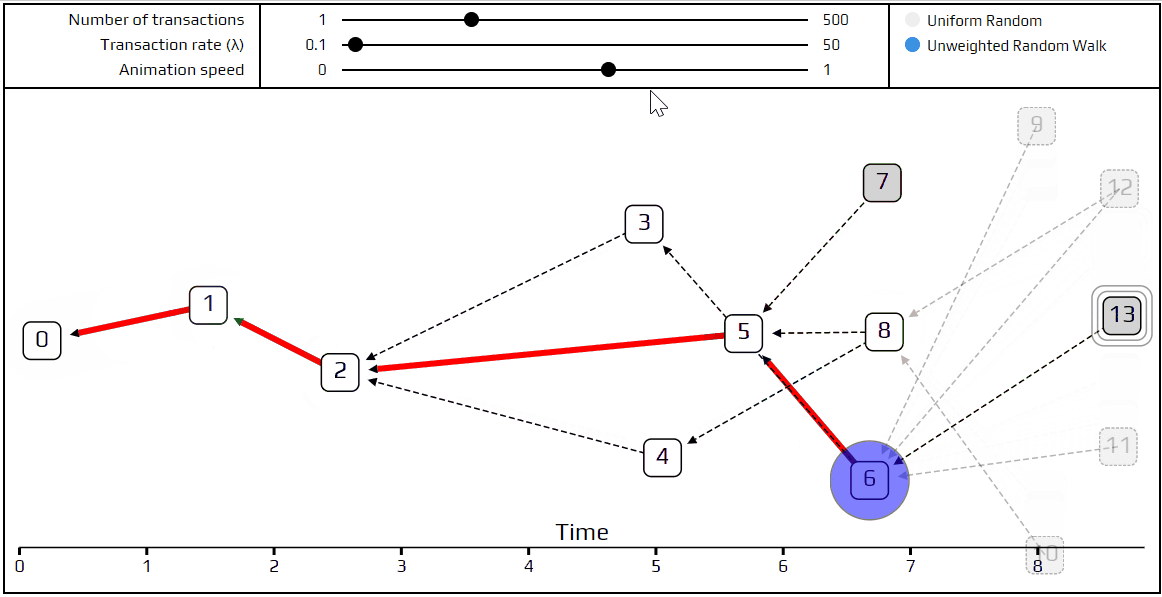
You can see the path the walker follows is marked in red, and at each junction, the different possible paths are marked in blue. Very recent transactions, which are “invisible” to the current random walk, are shown as transparent.
We covered a lot today, so please take your time to review the article, play with the simulation, and ask questions. You are welcome to contact me directly on Discord at @alongal#3938, or reply in the comments below. Next week, we'll learn about cumulative weights, Markov Chain Monte Carlo, and weighted random walks.
Part 1: Introduction to the Tangle
Part 3: Cumulative weights and weighted random walks
Part 4: Approvers, balances, and double-spends
Part 5: Consensus, confirmation confidence, and the coordinator
Follow us on our official channels for the latest updates
Discord | Twitter | LinkedIn | Instagram | YouTube


